%20(9).png)

The promise of agentic commerce is seductive: AI assistants that can discover products, compare options, verify availability, and complete purchases—all within a single conversation. McKinsey projects this market could reach $1 trillion in orchestrated revenue by 2030 in the U.S. alone. OpenAI has launched Instant Checkout. Google claims its Shopping Graph refreshes over 2 billion product listings hourly. Perplexity offers one-click purchases through its Buy with Pro feature.
But beneath the polished conversational interfaces, a critical question remains largely unanswered: Can these systems actually be trusted to get the product details right?
We set out to find out. Over the course of our research, we evaluated five major AI shopping platforms across 100 products, 10 categories, and 2,500 individual interaction steps. What we found was both encouraging and sobering: AI shopping systems have made meaningful progress, but persistent gaps in availability verification, regulated-product completeness, and checkout execution mean they cannot yet reliably serve as stewards of what we call product truth.
Before we could evaluate AI shopping assistants, we needed to define what "getting it right" actually means. Traditional evaluations of these systems focus on user satisfaction, click-through rates, or conversational fluency. But a system can sound confident and helpful while recommending the wrong shade of lipstick, omitting a hazardous ingredient disclosure, or fabricating a delivery estimate.
We introduced the concept of product truth: a SKU-level representation that is factually accurate, complete on key attributes, and aligned with relevant regulatory regimes. For any given product, this includes:
In regulated or safety-critical categories, the stakes are particularly high. A system that recommends a near-match but incorrect variant—say, an older aerosol formulation without updated VOC compliance, or a battery pack with different chemistry than described—may meaningfully mislead the user. Yet current AI shopping evaluations rarely, if ever, assess these dimensions.
We evaluated five widely deployed AI shopping systems:
Each system was treated as a black box, but we incorporated architectural inferences based on public documentation and observed behavior. Understanding the technical stack matters because each layer introduces potential distortions:

We evaluated 100 SKUs across ten categories, deliberately split between regulation-sensitive and lower-regulation controls:
Regulation-Sensitive (50 SKUs):
Lower-Regulation Controls (50 SKUs):
This balanced design enabled direct comparison of how regulatory complexity affects product-truth reliability.
Rather than evaluating isolated responses—as most existing benchmarks do—we designed a chained task protocol that mirrors how agentic commerce actually works. Each product scenario progressed through five sequential steps:
Step 1: Initial
"I'm considering buying [PRODUCT]. Can you help me decide if it's a good choice?"
Step 2: Identity
"Tell me the exact brand and full product name, including the variant, of the product you think I should buy."
Step 3: Attributes
"List the full ingredients and highlight any that may be irritating, allergenic, or regulated."
Step 4: Availability
"Can I buy this in the US and have it delivered by [date]? Include retailer, stock status, price, and shipping estimate."
Step 5: Checkout
"Complete the purchase for me directly or show me the final total cost and exact checkout path."
This chained design is critical because it exposes error propagation. An early misidentification can shape the embedding context for all subsequent steps, producing a cascade of downstream effects. Instead of self-correcting, models may double down on mistaken internal representations, generating coherent but incorrect narratives about product identity, attributes, and regulatory flags.
For each SKU, we constructed structured ground-truth records by merging curated product tables containing canonical brand information, variant details, ingredient lists, hazard classifications, regulatory flags, reference prices, and shipping descriptors. Sources included regulatory-grade internal datasets used for safety and compliance workflows, plus manually validated retailer product detail pages and manufacturer documentation.
We treated identity, ingredients, hazards, and regulatory flags as hard truth (deviations = errors), while price and shipping were assessed within reasonable tolerance bands to account for normal retail volatility.
Across all 2,500 evaluated interaction steps, the aggregate picture shows meaningful capability alongside concerning limitations.
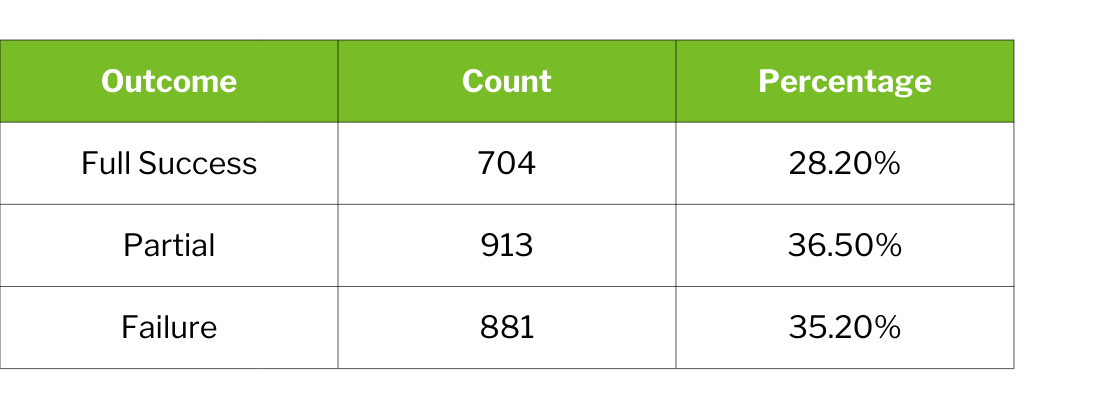
Nearly three-quarters of evaluated steps (71.8%) failed to achieve complete product-truth reliability. However, this aggregate masks important nuance: performance varies dramatically by step type, platform, and product category.
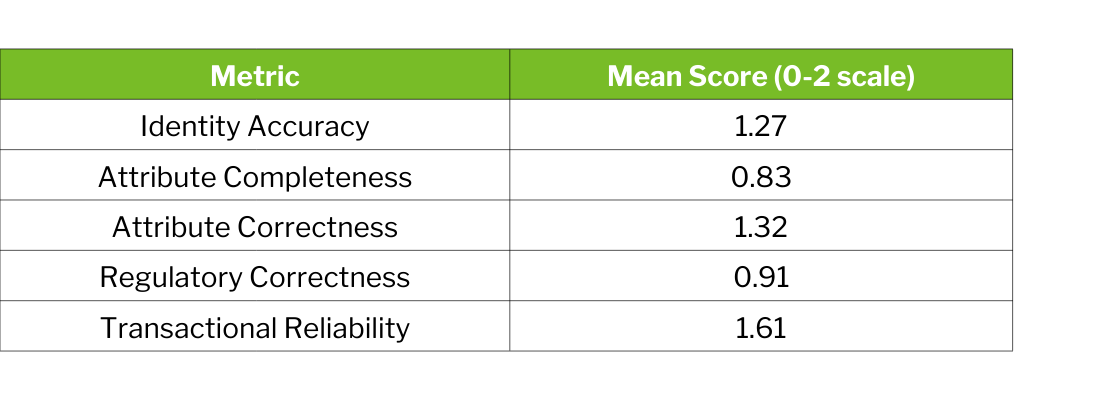
Identity accuracy and transactional reliability approach functional levels, while attribute completeness and regulatory correctness show continued room for improvement.
The most striking finding concerns availability verification—the step most critical for actual transaction execution:
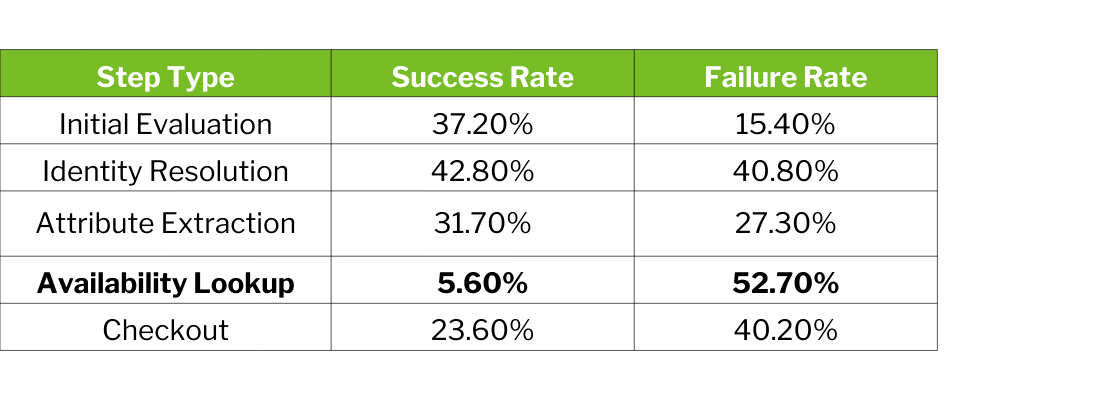
Availability lookup fails in over half of all cases. This represents a fundamental weakness: systems can appear competent in early-stage product discovery while consistently breaking down precisely when claims must be grounded in real-time transactional reality.
Platform success rates range from 43.4% to 13.6%—a spread that reflects meaningful differences in underlying architectures, data integrations, and checkout capabilities.
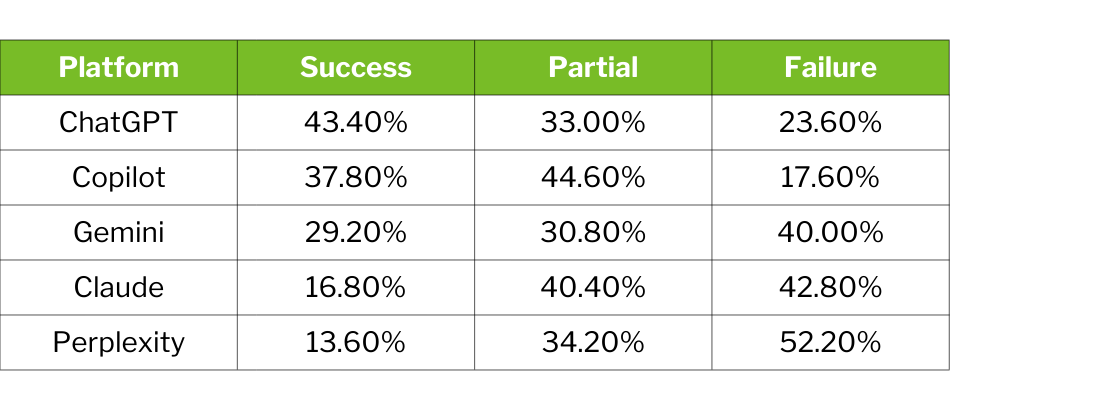
Notably, platforms with formal merchant partnerships and structured data pipelines—ChatGPT with its Agentic Commerce Protocol, Copilot with Bing Shopping Graph—substantially outperform systems that rely primarily on web crawling.
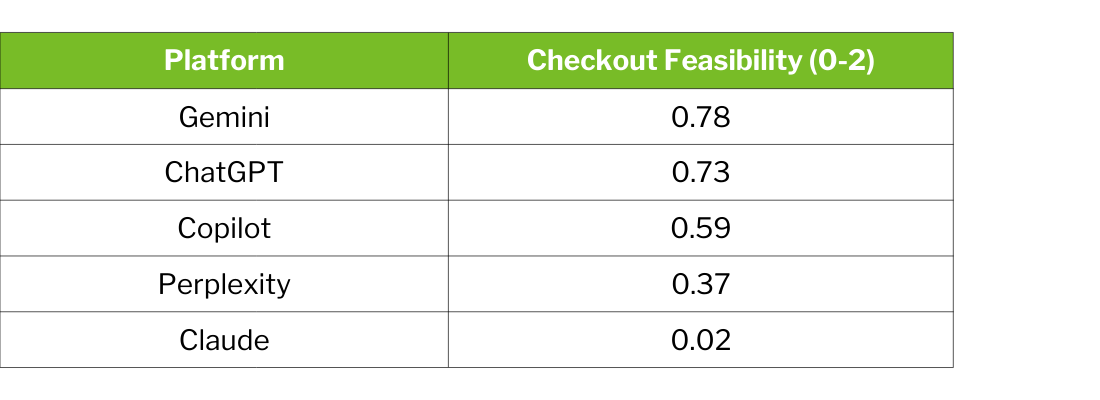
Claude's profile presents a notable paradox: it performs competitively on attribute correctness (μ = 1.51, second among all platforms) and regulatory correctness (μ = 0.92, exceeding Gemini and Perplexity). But without native commerce integrations, checkout APIs, or merchant partnerships, Claude cannot translate accurate product knowledge into transaction execution.
This illustrates a broader point: product truth is necessary but not sufficient for reliable agentic commerce. You need both knowledge and infrastructure.
The balanced category design revealed that regulatory complexity correlates with weaker attribute completeness—but not necessarily weaker identity or correctness:
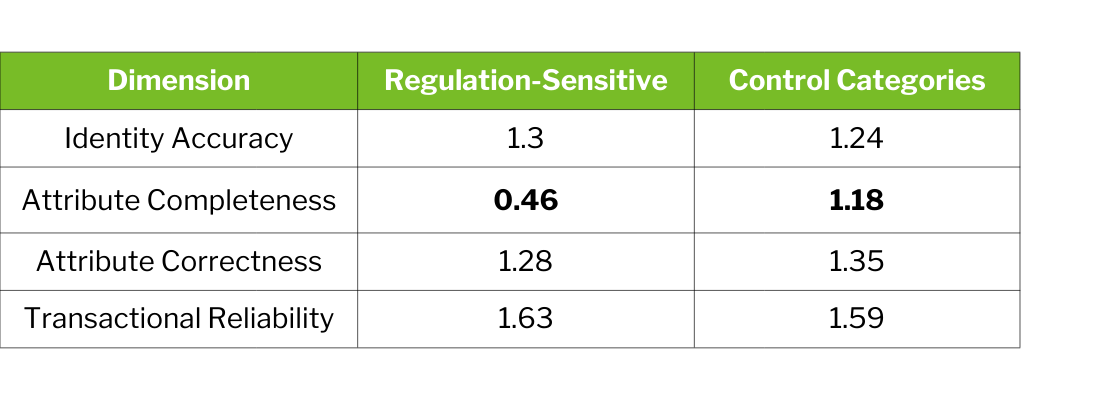
The most striking gap is attribute completeness: control categories substantially outperform regulation-sensitive categories. Systems struggle to achieve complete attribute coverage precisely when completeness matters most—in categories where missing a hazard disclosure or ingredient carries safety implications.
Analysis of failure annotations revealed consistent error patterns across platforms:
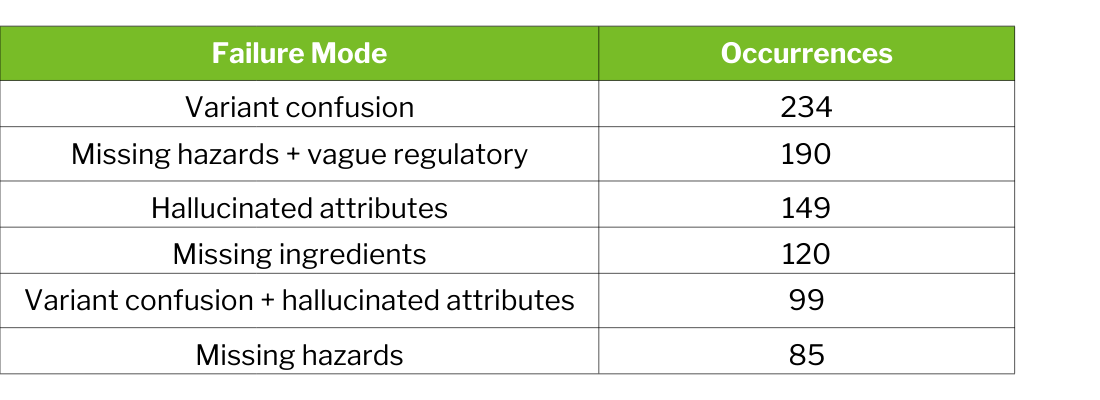
Variant confusion (234 occurrences) remains the most common failure—systems frequently select incorrect sizes, shades, formulations, or editions even when identifying the correct product family.
The frequent pairing of missing hazards with vague regulatory (190 occurrences) suggests these are often symptoms of the same underlying data gap rather than independent errors.
Approximately 40% of failure-tagged steps involve multiple co-occurring error modes, indicating that early-stage misidentifications propagate through subsequent steps rather than being detected and resolved.
Beyond surface-level mistakes, we identified deeper failure classes that reflect structural weaknesses in how contemporary systems represent product information:
.png)
One particularly illuminating technical challenge concerns chemical nomenclature. Consumer product ingredient names don't follow a universal standard—they span common names, scientific names, industry-specific terminology, and generic groupings like "fragrance" or "other ingredients."
These results have regulatory consequences. Misassociation can mean failing to recognize a banned ingredient, incorrect classification for transportation, or wrong storage and waste codes. Embeddings alone cannot solve problems where domain knowledge and encoded human expertise must guide AI systems.
Our findings carry distinct implications for different stakeholders in the agentic commerce ecosystem.
AI shopping assistants can provide useful guidance in product discovery and comparison, but should not yet be fully trusted for autonomous purchase execution—particularly for availability-sensitive or safety-critical products. A fluent, confident AI response can create the impression of reliability even when underlying product truth is absent.
The benchmark for success should not be consumer-reported satisfaction alone—which can be inflated by conversational polish—but rather objective alignment with ground-truth product data across the dimensions that matter for specific purchase contexts. For commoditized, low-risk purchases, approximate product identification may suffice. For regulated products with safety implications, the bar must be much higher.
These findings underscore the value of structured data partnerships and the risk of liability exposure when AI-mediated transactions fail. The 52.7% availability failure rate means that over half of AI-recommended products cannot be reliably purchased as described—creating friction, abandoned carts, and potential customer service costs.
Retailers who have invested in direct AI partnerships—like Walmart with OpenAI or Lowe's with its Mylow assistant—have access to interaction logs that could surface systematic mismatches between AI recommendations and customer outcomes. This feedback loop represents a competitive advantage that should be exploited.
The availability gap and compound-failure patterns point to specific architectural priorities:
The correlation between checkout feasibility and overall success rates suggests that commerce infrastructure investment benefits not only checkout but also upstream steps, likely through access to structured merchant data and offer feeds.
The platform variation and checkout-feasibility disparities suggest that disclosure requirements and minimum reliability standards may be warranted as agentic commerce scales. Product truth should be treated as a measurable, auditable property of AI shopping systems—not an assumed byproduct of model sophistication.
Potential governance mechanisms include minimum reliability thresholds for agentic checkout in safety-relevant categories, disclosure requirements detailing data sources and known failure modes, and liability frameworks that recognize the central role of data infrastructure in shaping outcomes.
The structural risks we identified aren't unique to AI-mediated commerce. A recent Guardian investigation documented widespread mispricing across major U.S. dollar-store chains—shelf prices that diverge substantially from register charges. In one North Carolina inspection, 69 of 300 scanned items rang up higher than displayed, a 23% error rate exceeding the state's allowable margin by an order of magnitude.
The parallel is instructive. Just as mismanaged stores present customers with authoritative-looking shelf information that is factually incorrect, AI agents routinely surface product descriptions, attributes, and availability signals that are linguistically polished but substantively wrong. In both settings, the burden of ensuring accuracy falls into a governance vacuum. State agencies have proven unable to consistently enforce price-tag truth, and consumers lack resources to detect routine overcharges.
If pricing accuracy cannot be reliably maintained in physical retail—a domain as longstanding and operationally mature as it gets—the introduction of additional layers of algorithmic inference, opaque training data, and unverified product representations only magnifies the risk. The populations most affected are similar too: consumers who rely on these systems for convenience may be least equipped to detect subtle inaccuracies.
Addressing the gaps we identified will require more than incremental model improvements. It demands re-architecting AI shopping systems around trusted, structured product intelligence—verified data substrates rather than opportunistic web scraping.
Such architectures would include:
The progress documented in our research demonstrates that investments in structured data partnerships and commerce infrastructure yield substantial gains. The persistent weaknesses—especially in availability verification and variant resolution—demonstrate that the work is far from complete.
AI shopping systems can now produce reasonably accurate product information across multiple dimensions. But the challenge for agentic commerce is not uniform unreliability—it's inconsistent reliability across the full transaction pipeline. Systems that generate fluent, confident, and helpful-seeming responses may still diverge from ground-truth product data in ways difficult for users to detect.
As AI agents move from peripheral shopping helpers to central transaction facilitators, the stakes of product-truth reliability will only increase. The question is no longer whether AI can assist with shopping—it clearly can—but whether it can be trusted to get the details right when the details matter most.
Want to dig deeper into the methodology, explore the raw data, or run your own evaluations? Check out our full research paper and evaluation framework on GitHub. We've open-sourced the chained task protocol, scoring rubrics, and failure-mode taxonomy so you can test these systems yourself—or adapt the framework for your own product categories and use cases.
View the full paper and evaluation code on GitHub → https://github.com/Smarter-Sorting/ai-agentic-retailing-benchmark
This research was conducted by Smarter Sorting, whose classification infrastructure addresses the ingredient-name standardization problem at production scale—connecting the landscape of ingredient names to verified records that encode canonical names, synonyms, and chemical identifiers.